
There is a constant in my life, and I believe in most people's lives as well: change. Some people would rather it never happen; they hold on as much as possible, clinging to any situation or thing that keeps change far away. Others don't; they crave change, want it to happen all the time, are eager, and believe that only through change will the world move forward.
I prefer to believe I'm in the middle, or maybe to convince myself I'm in the middle. However, throughout my life, I decided and learned that the middle path is neither better nor worse; it is mediocre, but at the same time comforting. Comforting because, in the case of change, you don't suffer if it comes in a harsh and abrupt way, and you also don't suffer if it never comes and stagnation lasts for a while.
In the present moment, as much as some people don't like it (or don't want to accept it), we are going through a period of change. Some call it revolution, evolution, or any more poetic name that brings to the surface the most dangerous longings or daydreams of our minds.
I'm calling it CHANGE, for the simple fact that we are changing, adapting, learning, and understanding the limits of what this technology is capable of.
Coincidence or not (there are no coincidences, right?), the week I wrote this introduction, Brittany Ellich wrote a nice article (Living in the inflection point) about this change. I don't agree with every point, but I think it's an interesting complementary read for you, dear reader.
Vibe Coding
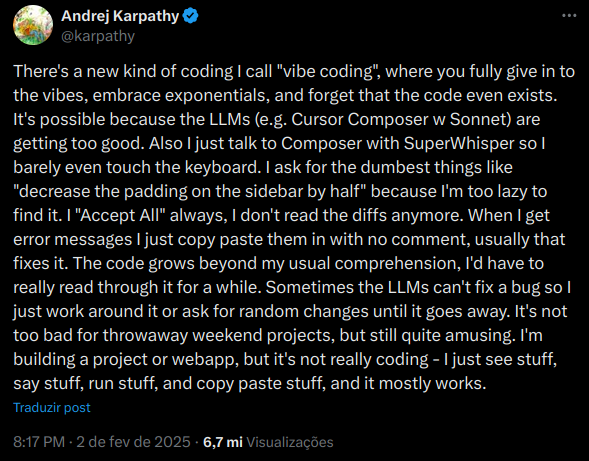
The term was coined in February 2025 by one of today's leading Artificial Intelligence researchers/engineers: Andrej Karpathy.
I don't want to spend too much time navigating this topic, because I've already discussed what it is, how people misuse the term, etc. So I'll leave here the image of Karpathy's original tweet explaining exactly what vibe coding is.
Complexity is hard
One of the great challenges of engineering and, consequently, of computer science is to transform complex problems that live in the abstract world of ideas into something “tangible” (or as tangible as software can be). Over decades, this has been a problem hundreds of thousands of people work on every day, greatly advancing the way we live today.
The complexity of a problem can be so large that an entire discipline was defined to classify problem complexity, a field we denote as Computational Complexity Theory.
Therefore, saying that developing software is easy, simple, or fast depends heavily on how complex the idea is that we want to materialize. However, over the last decades, many techniques, frameworks, and processes have tried to make it easier to materialize new ideas, which over time ended up creating the perception that building entire systems is a trivial, low-complexity task that anyone can do quickly with little knowledge (what many call the democratization of software). For many who have been in the field for years, and for those who enter with that mindset, reality ends up showing this is not true: materializing ideas in software is complex and demands time and study.
Code generation
And here we are, at this point, this exact moment of change. A change that, as I mentioned at the beginning of this text, is still happening, and we are learning and adapting to it. This change is the automatic generation of code; that is, the materialization of an idea into software.
For many years, this was a goal pursued by some: to avoid this complexity directly by using some kind of tool that would turn an idea into software. Over the years, we had several tools that try, objectively, to do this, and along with them came new terms and definitions, such as Low-Code and No-Code.
However, despite being able to materialize an idea up to a certain level of complexity, these tools have major limitations and still need a key piece to do their work: a human operator.
The world of Artificial Intelligence: generators of blabber
We arrive at the year 2017, when the current base architecture of LLMs was created: the so-called Transformers. From that point on, much of the research aimed at translating text between different languages began to change, but, above all, it was discovered that generating the next word (or token, as it's always repeated) was not merely probabilistic, but something special.
There is a theorem that I think fits well with the current state of LLMs: the Infinite Monkey Theorem (Infinite monkey theorem). Why do I think that? Think about what the theorem tells us:
"The infinite monkey theorem states that a monkey hitting keys independently and at random on a typewriter keyboard for an infinite amount of time will almost surely type any given text, including the complete works of William Shakespeare."
Perhaps we can imagine an LLM as a monkey probabilistically choosing the next words over a certain period of time, within a reduced (but gigantic) sample space. This makes me think that it might be able to generate something “sensible,” depending on the context and the probabilities within that sample space.
Therefore, the criticism that LLMs generate garbage is true, because they are basically generating something “random” for the given context, within their space of “knowledge.” However, not all garbage is disposable, and just like in real life, garbage can have a use, and depending on the quality of the garbage, it can have value if it's recyclable.
Understand that this is a defense, somewhat shallow, but still a valid defense for many cases. And for now (despite some opposing evidence: "Scale Is All You Need" is dead), the larger the sample space, the higher the quality of the generated garbage.
Another interesting video on the topic that's worth watching and relates directly to all of this:
AI can't cross this line and we don't know why.
My point here is that, given a context, if the model has “capacity” within the sample space it was trained on to return high-quality garbage, that's what it will return. I like to say that the output of a generative network is the average of what it “learned” (even though that's not true, it may help illustrate for a lay reader how this technology more or less works): if it “learned” more high-quality knowledge, the returned average will be better.
The Project
This brings us to the main project this blog post is being written for: using vibe coding and the latest released models to create a complete text editor (almost an IDE).
Thinking in a practical and honest way, creating a text editor is not new. It's complex, but not new; there are and have been many other tools in the market and open source that do EXACTLY this.
Some examples:
- VS Code
- All JetBrains IDEs
- Eclipse
- Netbeans
- Sublime Text
- Zed
- Vim and NeoVim
- Emacs
- Among many others
Therefore, it's feasible to say that an LLM could indeed create a text editor “from scratch,” and that's exactly what this project is about.
P.S.: I originally started writing this blog post in VS Code, where I wrote all my posts, but at the moment (which is basically this entire section and the next ones), all of this is being written in the new editor I called Ehwaz.
Ehwaz, the editor

The idea here was to create a text editor using the Rust programming language. The reason for this choice is quite simple: I've seen many people saying that LLMs don't know how to write Rust correctly, or that they write it with many errors, and that iterating is a problem.
So, I decided to validate this premise using only “root” vibe coding (“root” because nowadays Karpathy's definition that I brought up at the beginning is quite distorted, and using any kind of agent for any task is considered vibe coding): just interacting with the LLM and asking what to do and how to do it (change layout, implement feature X, fix bug Y).
In the end, the editor came out, and it came out better than I expected... Whether it's a good enough editor to compete with others in the market, with years of development and dozens or hundreds of developers, I'll leave it up to you, reader, to judge (I'd say no, but to each their own madness, right?).
What I can objectively say is that building this editor took about 1 week and consumed about 45 dollars (10 from my standard GitHub Copilot account, plus 35 extra that I added throughout the period as I wanted to go further with more features).
Here is the repository so you, dear reader, can evaluate it: Ehwaz
The models!
Well, as I said, the premise was to evaluate how good the models would be at creating a text editor using Rust from scratch. When I thought about doing this, perhaps by coincidence (we've already said here that there are no coincidences, right?), both Anthropic and OpenAI released their new models for coding: Opus 4.6 and Codex 5.3.
Since OpenAI takes a bit to release their new models via API, I started the project using Opus 4.6. The model worked very well and I managed to create an initial base for the project, as I said, using vibe coding.
But, for that reason, I included an entire section in this blog post commenting on complexity: I had a couple of problems (actually, two problems) where Claude Opus 4.6 simply couldn't make progress:
- Calculating the cursor position within the component created for text editing;
- Embedding a terminal inside the editor;
In both features, Opus 4.6 had immense difficulty fixing small details and bugs, especially when it came to calculating element positioning.
I even suggested to Opus that it scan several other open source editor projects to understand how those editors calculate positioning. In the second case, the terminal case, that helped somewhat, since Ehwaz basically uses the same component that Zed uses (in this case, Alacritty).
In the case of the cursor positioning inside the editor, I spent many iterations trying to get it to fix it, but even so, nothing worked. Only with Codex 5.3 did I basically manage to ask the LLM to fix the small problems and details in both cases.
From that point on (when OpenAI released Codex 5.3 and Microsoft added it to GitHub Copilot), the project gained more momentum for two reasons:
- Models better than or comparable to Opus 4.6;
- Lower token usage for the same activity;
The second item was essential: with lower token usage, it was possible to go further while basically spending less money.
Does that mean using Codex 5.3 is better than Opus 4.6?
I'd say: it depends. Since LLMs are probabilistic models and context strongly influences a possible correct output, that may have happened here. It may be that Codex 5.3 is better at solving Rust problems with UI that already exist (it may be that Codex was trained on lots of code from other existing editors).
Quality and Responsibility
Regarding the quality of the generated code, I believe it is certainly questionable, but I took some precautions. Which means that, in fact, at various moments I asked the model to do:
- Refactoring
- Review
- Code separation (by domain)
- Performance improvements
- Finding hot spots / problematic areas
- Where it made sense, maybe using threads or async (and here I also asked the model which would be the better option).
Therefore, if someone goes to explore the codebase, they will notice several of these aspects within it. But they are certainly “thrown in” and randomly defined according to how the LLM interprets each of these cases.
You, dear reader, can also check the RULES.md that I created for the project and loaded at the beginning of every session I opened with the GitHub Copilot CLI, and which I would sporadically reload when context started getting lost.
This leads me to believe that, although it's possible, we have several problems that must be considered when we create software using vibe coding.
-
Not having mastery over the code: since the entire code was created via vibe coding, I have no control over whether it's good or not, whether it has bugs or serious security issues. If the LLM didn't point that out or fix it, the problem is there;
-
How to fix bugs or add new features: software created this way implies that for any bug or new feature, we have to learn how the codebase works, or go by trial and error and use vibe coding to implement the bug fix or feature;
-
No guarantees: how can someone guarantee anything without knowing exactly what's implemented? You can claim you guarantee something, but the truth is that this is a lie; your guarantee lasts only until an error happens.
Final Thoughts
Personally, I enjoyed running this test project, and it was interesting to observe how the new models work and what was good or not to use. I see value in using LLM models for advanced code completion, or even for code evaluation or suggestions, but the idea of letting an agent create everything from scratch and carry the project forward as a whole, without you being directly involved, is a direction I don't agree with.
The reason for this disagreement has nothing to do with AI taking people's jobs or anything like that, but rather that, up to the present moment, we don't have any tool that operates alone without human intervention, and that can lead to real problems without people understanding why it happened.
All of this, as I started this text, brings changes far greater than the ones we effectively want to happen in our society: losing responsibility for what is built and maintained over time.
As for Ehwaz, I will continue “supporting” its development, and it will continue being vibe coding. It's a personal project, a POC FOR ME.
THEREFORE, DO NOT USE IT, ONLY TEST IT AND SEE IT AS AN EXPERIMENT!
If you have questions, I'll be happy to answer or maybe help; just reach out to me on social networks!
Hugs, and see you next time!